


As a fun side project, I've been gathering data on bills that are going through the U.S Senate. So far, the site itself is a pretty simple web app to display bill status information in an easier to digest format. This is the first step of many in my goal for an in-depth analysis of the different of bills that are going through the Senate (and eventually House of Representatives). Through integration with other publicly available data hopefully we can gather some interesting insights that are not normally readily available to a layperson.
In a series of blog posts, I'm going to use some basic NLP to analyze the bills that have gone through the Senate for the past year and show some pretty charts.
All code used for this analysis is available here: https://github.com/a5huynh/bill-analysis
Gathering the Data
Bulk congressional data is publicly available as XML for the 115th, 114th, and 113th congress via the Congressional Bulk Data site. There are additionally some useful guides and schema docs on Github, made publicly available by the USGPO.
Looking at the bulk data site, the information we are interested in is divided into:
BILLS: Contain the full text of the bill.BILLSTATUS: Contains information about that status of the respective legislation, who (co)sponsored the legislation, and a history of actions that have been taken.BILLSUM: Contains a short summary text of the bill in question.
For this analysis, I'll be using the data available in the BILLS and
BILLSTATUS buckets. If you have clone/forked my previously mentioned
repository, you can run the following command in the root directory to
download and setup the data folders.
make dl-data
XML to Plain text
First off, we need to convert the XML formatted data into something suitable for our analysis. Looking at the XML files we've unpacked and using python's built-in XML parsing utilities, we can see that the documents are divided into three sections:
metadataformlegis-body: This doesn't appear in every file, just ones that are new legislation.- Amendments will have the
amendmenttag in place oflegis-body.
We're interested in text in the legis-body section, a snippet of which I
pulled out and show below:
<enum>2.</enum>
<header>
Special resource study of James K. Polk presidential home
</header>
<subsection id="id7de0f50b003d4fde9ed1f7dc4c7214b2">
<enum>(a)</enum>
<header>Definitions</header>
<text>In this section:</text>20
<paragraph id="idB162332A1BCB420685364EB582B8E9D6">
<enum>(1)</enum>
<header>Secretary</header>
<text>
The term <term>Secretary</term> means the
Secretary of the Interior.
</text>
</paragraph>
In each <legis-body> tag there are sections, sub-sections, unique
identifiers, headers, and enums some of which may or may not be useful. For
simplification, we'll only look at text in the <text> tags and toss
out everything else, turning the above XML into the text snippet below:
This Act may be cited as the James K. Polk Presidential Home Study Act.
In this section: The term Secretary means the Secretary of the Interior.
Tokenization & Stemming
Now that we have plain text, next up is tokenizing and stemming the plain text from the previous step.
Tokenization chops up the plain text into an array of strings and throwing away certain characters, such as punctuation/numbers and stop words. Stemming takes this further and allows us to map related words to a single token across an entire corpus. For example, the words "stem", "stemming", "stemmed" can all be mapped to the token "stem" for the sake of analysis.
Below, I've pulled out the code snippet used in the repository to extract and stem the tokens. This is accomplished with a combination of features from spaCy.
import spacy
NLP = spacy.load('en', disable=['parser', 'ner', 'textcat'])
def txt_to_token(txt : str):
results = []
for token in NLP(txt):
# Ignore numbers, stop words, and punctuation
if not token.is_alpha or token.is_stop \
or token.is_punct or token.is_space:
continue
results.append(token.lemma_)
return results
As a side note, I just want to note that the
spaCydocumentation is well designed and was really a pleasure to read through and use during this process.
Running Simple Analyses
When I started down the path for this blog post I was interested in uncovering a couple things from the dataset:
- Topics of interest often discussed in bills.
- Interesting trends over the years, perhaps correlated with the political makeup of the Senate.
- Anything else we can scrounge up.
Lets start with topics of interest. With the tokens we've created in our data preparation step, we can play around with some statistics of the corpus to find anything interesting.
I'll first start with a basic, word frequency chart just to see if there's anything unexpected.
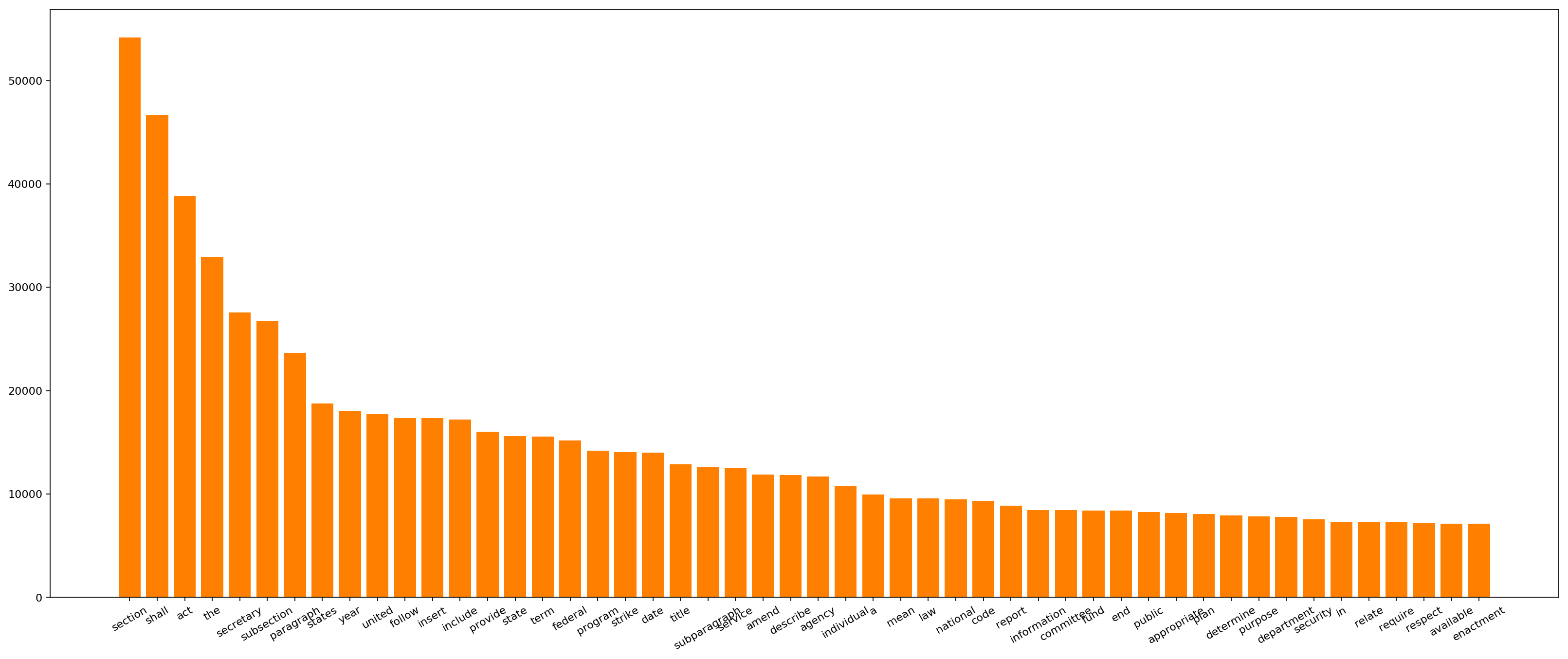 A visualization of the 50 most frequent tokens. Click here
for the full image.
A visualization of the 50 most frequent tokens. Click here
for the full image.
The top 50 tokens seem normal based on the corpus of data. There are plenty
of ones we'd expect in legislation and some interesting tokens (e.g.
security and health) that may point to topics that are most discussed
in these bills. However, overall, not immensely useful until we can remove
tokens that are present in all documents.
To ignore tokens that appear throughout the entire corpus and bubble up words that may be more interesting, lets use TF-IDF with some constraints on the max document frequency to get a list of important tokens in the corpus.
What is TF-IDF?
TF-IDFincreases the score of a token proportionally by how many times it shows up in a document, offset by the number of times the token shows up in the entire corpus.
With scikit-learn, calculating the tf-idf score for all documents is super easy. Here's a small snippet that demonstrates the calculation
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(
max_df=0.5,
# Note: Since we've already tokenized the documents in
# the data preparation step, we'll skip these steps
# in the TfidfVectorizer.
preprocessor=lambda x: x,
tokenizer=lambda x: x
)
# Features contains all the tokens as used by TfidfVectorizer
features = tfidf.get_feature_names()
# Create a matrix where each row represents the tf-idf vector
# for a particular document.
scores = tfidf.fit_transform(token_dict.values())
With the scores in a matrix, we can easily average the tf-idf scores and
pull the tokens with the top scores to get a general sense of the important
tokens in the entire corpus. Below is a visualization of those scores
which seems to give a better sense of legislative topics, such as
security, health, education, etc.
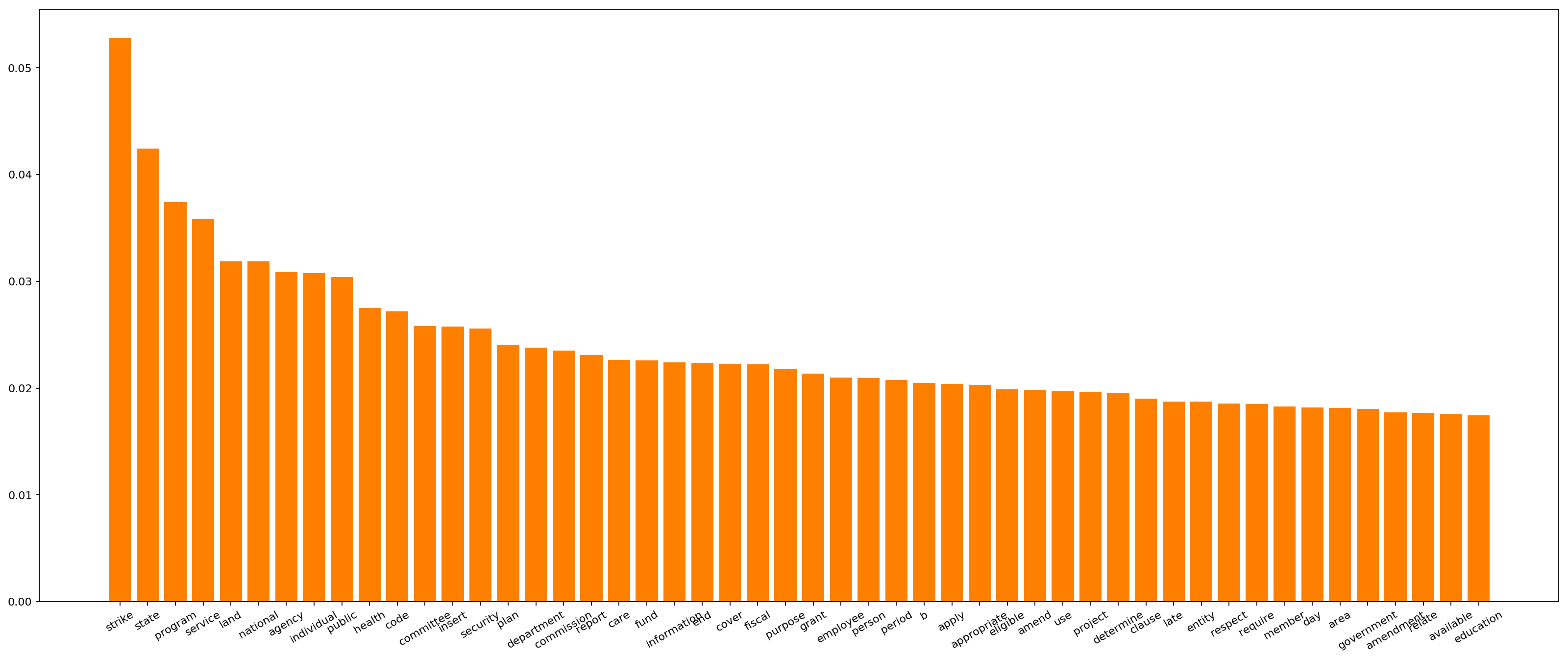 A visualization of the top 50 words by tf-idf. Click here
for the full image.
A visualization of the top 50 words by tf-idf. Click here
for the full image.
Discussion & Next Time
That's it for now!
In the next part of this series, I'll dig a little deeper into the content
of the bills and correlate topics with how likely things are to make it all
the way through the Senate. We'll additionally take a look at the
BILLSTATUS dataset and use it conjunction with the BILLS dataset for
more interesting insights.